import pandas as pd5 Series Deepdive
Source: https://github.com/mattharrison/effective_pandas_book
url = 'https://github.com/mattharrison/datasets/raw/master/data/' \
'vehicles.csv.zip'df = pd.read_csv(url)
city_mpg = df.city08
highway_mpg = df.highway08/var/folders/70/7wmmf6t55cb84bfx9g1c1k1m0000gn/T/ipykernel_6435/3976941641.py:1: DtypeWarning: Columns (68,70,71,72,73,74,76,79) have mixed types. Specify dtype option on import or set low_memory=False.
df = pd.read_csv(url)city_mpg0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: int64highway_mpg0 25
1 14
2 33
3 12
4 23
..
41139 26
41140 28
41141 24
41142 24
41143 21
Name: highway08, Length: 41144, dtype: int64len(dir(city_mpg))4195.1 Dunder Methods
2 + 46(2).__add__(4)6(city_mpg + highway_mpg)/20 22.0
1 11.5
2 28.0
3 11.0
4 20.0
...
41139 22.5
41140 24.0
41141 21.0
41142 21.0
41143 18.5
Length: 41144, dtype: float645.2 Index Allignment
When you operate with two series, pandas will align the index before performing the operation. Aligning will take each index entry in the left series and match it up with every entry with the same name in the index of the right series.”
Because of index alignment, you will want to make sure that the indexes:
- Are unique (no duplicates)
- Are common to both series
s1 = pd.Series([10, 20, 30], index=[1,2,2])
s2 = pd.Series([35, 44, 53], index=[2,2,4], name='s2')
s11 10
2 20
2 30
dtype: int64s22 35
2 44
4 53
Name: s2, dtype: int64s1 + s21 NaN
2 55.0
2 64.0
2 65.0
2 74.0
4 NaN
dtype: float64s1.add(s2, fill_value=0)1 10.0
2 55.0
2 64.0
2 65.0
2 74.0
4 53.0
dtype: float64((city_mpg +
highway_mpg)
/ 2
)0 22.0
1 11.5
2 28.0
3 11.0
4 20.0
...
41139 22.5
41140 24.0
41141 21.0
41142 21.0
41143 18.5
Length: 41144, dtype: float64(city_mpg
.add(highway_mpg)
.div(2)
)0 22.0
1 11.5
2 28.0
3 11.0
4 20.0
...
41139 22.5
41140 24.0
41141 21.0
41142 21.0
41143 18.5
Length: 41144, dtype: float64city_mpg.mean()18.369045304297103city_mpg.is_uniqueFalsecity_mpg.is_monotonic_increasingFalsecity_mpg.quantile()17.0city_mpg.quantile(.9)24.0city_mpg.quantile([.1, .5, .9])0.1 13.0
0.5 17.0
0.9 24.0
Name: city08, dtype: float64(city_mpg
.gt(20)
.sum()
)10272(city_mpg
.gt(20)
.mul(100)
.mean()
)24.965973167412017city_mpg.agg('mean')18.369045304297103import numpy as np
def second_to_last(s):
return s.iloc[-2]city_mpg.agg(['mean', np.var, max, second_to_last])mean 18.369045
var 62.503036
max 150.000000
second_to_last 18.000000
Name: city08, dtype: float64city_mpg.convert_dtypes()0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: Int64city_mpg.astype('Int16')0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: Int16city_mpg.astype('Int8')--------------------------------------------------------------------------- TypeError Traceback (most recent call last) ~/envs/menv/lib/python3.8/site-packages/pandas/core/arrays/integer.py in safe_cast(values, dtype, copy) 125 try: --> 126 return values.astype(dtype, casting="safe", copy=copy) 127 except TypeError as err: TypeError: Cannot cast array data from dtype('int64') to dtype('int8') according to the rule 'safe' The above exception was the direct cause of the following exception: TypeError Traceback (most recent call last) <ipython-input-35-15ba00a8d273> in <module> ----> 1 city_mpg.astype('Int8') ~/envs/menv/lib/python3.8/site-packages/pandas/core/generic.py in astype(self, dtype, copy, errors) 5813 else: 5814 # else, only a single dtype is given -> 5815 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors) 5816 return self._constructor(new_data).__finalize__(self, method="astype") 5817 ~/envs/menv/lib/python3.8/site-packages/pandas/core/internals/managers.py in astype(self, dtype, copy, errors) 416 417 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T: --> 418 return self.apply("astype", dtype=dtype, copy=copy, errors=errors) 419 420 def convert( ~/envs/menv/lib/python3.8/site-packages/pandas/core/internals/managers.py in apply(self, f, align_keys, ignore_failures, **kwargs) 325 applied = b.apply(f, **kwargs) 326 else: --> 327 applied = getattr(b, f)(**kwargs) 328 except (TypeError, NotImplementedError): 329 if not ignore_failures: ~/envs/menv/lib/python3.8/site-packages/pandas/core/internals/blocks.py in astype(self, dtype, copy, errors) 590 values = self.values 591 --> 592 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors) 593 594 new_values = maybe_coerce_values(new_values) ~/envs/menv/lib/python3.8/site-packages/pandas/core/dtypes/cast.py in astype_array_safe(values, dtype, copy, errors) 1307 1308 try: -> 1309 new_values = astype_array(values, dtype, copy=copy) 1310 except (ValueError, TypeError): 1311 # e.g. astype_nansafe can fail on object-dtype of strings ~/envs/menv/lib/python3.8/site-packages/pandas/core/dtypes/cast.py in astype_array(values, dtype, copy) 1255 1256 else: -> 1257 values = astype_nansafe(values, dtype, copy=copy) 1258 1259 # in pandas we don't store numpy str dtypes, so convert to object ~/envs/menv/lib/python3.8/site-packages/pandas/core/dtypes/cast.py in astype_nansafe(arr, dtype, copy, skipna) 1103 # dispatch on extension dtype if needed 1104 if isinstance(dtype, ExtensionDtype): -> 1105 return dtype.construct_array_type()._from_sequence(arr, dtype=dtype, copy=copy) 1106 1107 elif not isinstance(dtype, np.dtype): # pragma: no cover ~/envs/menv/lib/python3.8/site-packages/pandas/core/arrays/integer.py in _from_sequence(cls, scalars, dtype, copy) 321 cls, scalars, *, dtype: Dtype | None = None, copy: bool = False 322 ) -> IntegerArray: --> 323 values, mask = coerce_to_array(scalars, dtype=dtype, copy=copy) 324 return IntegerArray(values, mask) 325 ~/envs/menv/lib/python3.8/site-packages/pandas/core/arrays/integer.py in coerce_to_array(values, dtype, mask, copy) 229 values = safe_cast(values, dtype, copy=False) 230 else: --> 231 values = safe_cast(values, dtype, copy=False) 232 233 return values, mask ~/envs/menv/lib/python3.8/site-packages/pandas/core/arrays/integer.py in safe_cast(values, dtype, copy) 131 return casted 132 --> 133 raise TypeError( 134 f"cannot safely cast non-equivalent {values.dtype} to {np.dtype(dtype)}" 135 ) from err TypeError: cannot safely cast non-equivalent int64 to int8
np.iinfo('int64')iinfo(min=-9223372036854775808, max=9223372036854775807, dtype=int64)np.iinfo('uint8')iinfo(min=0, max=255, dtype=uint8)np.finfo('float16')finfo(resolution=0.001, min=-6.55040e+04, max=6.55040e+04, dtype=float16)np.finfo('float64')finfo(resolution=1e-15, min=-1.7976931348623157e+308, max=1.7976931348623157e+308, dtype=float64)city_mpg.nbytes329152city_mpg.astype('Int16').nbytes123432make = df.make
make.nbytes329152make.memory_usage()329280make.memory_usage(deep=True)2606395(make
.astype('category')
.memory_usage(deep=True)
)95888city_mpg.astype(str)0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: objectcity_mpg.astype('category')0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: category
Categories (105, int64): [6, 7, 8, 9, ..., 137, 138, 140, 150]values = pd.Series(sorted(set(city_mpg)))
city_type = pd.CategoricalDtype(categories=values,
ordered=True)
city_mpg.astype(city_type)0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: category
Categories (105, int64): [6 < 7 < 8 < 9 ... 137 < 138 < 140 < 150]city_mpg.to_frame()| city08 | |
|---|---|
| 0 | 19 |
| 1 | 9 |
| 2 | 23 |
| 3 | 10 |
| 4 | 17 |
| ... | ... |
| 41139 | 19 |
| 41140 | 20 |
| 41141 | 18 |
| 41142 | 18 |
| 41143 | 16 |
41144 rows × 1 columns
def gt20(val):
return val > 20%%timeit
city_mpg.apply(gt20)4.48 ms ± 49.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)%%timeit
city_mpg.gt(20)76.7 µs ± 931 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)make = df.makemake0 Alfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: objectmake.value_counts()Chevrolet 4003
Ford 3371
Dodge 2583
GMC 2494
Toyota 2071
...
Volga Associated Automobile 1
Panos 1
Mahindra 1
Excalibur Autos 1
London Coach Co Inc 1
Name: make, Length: 136, dtype: int64top5 = make.value_counts().index[:5]
def generalize_top5(val):
if val in top5:
return val
return 'Other'make.apply(generalize_top5)0 Other
1 Other
2 Dodge
3 Dodge
4 Other
...
41139 Other
41140 Other
41141 Other
41142 Other
41143 Other
Name: make, Length: 41144, dtype: objectmake.where(make.isin(top5), other='Other')0 Other
1 Other
2 Dodge
3 Dodge
4 Other
...
41139 Other
41140 Other
41141 Other
41142 Other
41143 Other
Name: make, Length: 41144, dtype: object%%timeit
make.apply(generalize_top5)11 ms ± 76.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)%%timeit
make.where(make.isin(top5), 'Other')1.65 ms ± 35.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)make.mask(~make.isin(top5), other='Other')0 Other
1 Other
2 Dodge
3 Dodge
4 Other
...
41139 Other
41140 Other
41141 Other
41142 Other
41143 Other
Name: make, Length: 41144, dtype: objectvc = make.value_counts()
top5 = vc.index[:5]
top10 = vc.index[:10]
def generalize(val):
if val in top5:
return val
elif val in top10:
return 'Top10'
else:
return 'Other'make.apply(generalize)0 Other
1 Other
2 Dodge
3 Dodge
4 Other
...
41139 Other
41140 Other
41141 Other
41142 Other
41143 Other
Name: make, Length: 41144, dtype: object(make
.where(make.isin(top5), 'Top10')
.where(make.isin(top10), 'Other')
)0 Other
1 Other
2 Dodge
3 Dodge
4 Other
...
41139 Other
41140 Other
41141 Other
41142 Other
41143 Other
Name: make, Length: 41144, dtype: objectimport numpy as np
np.select([make.isin(top5), make.isin(top10)],
[make, 'Top10'], 'Other')array(['Other', 'Other', 'Dodge', ..., 'Other', 'Other', 'Other'],
dtype=object)pd.Series(np.select([make.isin(top5), make.isin(top10)],
[make, 'Top10'], 'Other'), index=make.index)0 Other
1 Other
2 Dodge
3 Dodge
4 Other
...
41139 Other
41140 Other
41141 Other
41142 Other
41143 Other
Length: 41144, dtype: objectcyl = df.cylinders
(cyl
.isna()
.sum()
)206missing = cyl.isna()
make.loc[missing]7138 Nissan
7139 Toyota
8143 Toyota
8144 Ford
8146 Ford
...
34563 Tesla
34564 Tesla
34565 Tesla
34566 Tesla
34567 Tesla
Name: make, Length: 206, dtype: objectcyl[cyl.isna()]7138 NaN
7139 NaN
8143 NaN
8144 NaN
8146 NaN
..
34563 NaN
34564 NaN
34565 NaN
34566 NaN
34567 NaN
Name: cylinders, Length: 206, dtype: float64cyl.fillna(0).loc[7136:7141]7136 6.0
7137 6.0
7138 0.0
7139 0.0
7140 6.0
7141 6.0
Name: cylinders, dtype: float64temp = pd.Series([32, 40, None, 42, 39, 32])
temp0 32.0
1 40.0
2 NaN
3 42.0
4 39.0
5 32.0
dtype: float64temp.interpolate()0 32.0
1 40.0
2 41.0
3 42.0
4 39.0
5 32.0
dtype: float64city_mpg.loc[:446]0 19
1 9
2 23
3 10
4 17
..
442 15
443 15
444 15
445 15
446 31
Name: city08, Length: 447, dtype: int64(city_mpg
.loc[:446]
.clip(lower=city_mpg.quantile(.05),
upper=city_mpg.quantile(.95))
)0 19.0
1 11.0
2 23.0
3 11.0
4 17.0
...
442 15.0
443 15.0
444 15.0
445 15.0
446 27.0
Name: city08, Length: 447, dtype: float64city_mpg.sort_values()7901 6
34557 6
37161 6
21060 6
35887 6
...
34563 138
34564 140
32599 150
31256 150
33423 150
Name: city08, Length: 41144, dtype: int64(city_mpg.sort_values() + highway_mpg) / 20 22.0
1 11.5
2 28.0
3 11.0
4 20.0
...
41139 22.5
41140 24.0
41141 21.0
41142 21.0
41143 18.5
Length: 41144, dtype: float64city_mpg.sort_values().sort_index()0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: int64city_mpg.drop_duplicates()0 19
1 9
2 23
3 10
4 17
...
34364 127
34409 114
34564 140
34565 115
34566 104
Name: city08, Length: 105, dtype: int64city_mpg.rank()0 27060.5
1 235.5
2 35830.0
3 607.5
4 19484.0
...
41139 27060.5
41140 29719.5
41141 23528.0
41142 23528.0
41143 15479.0
Name: city08, Length: 41144, dtype: float64city_mpg.rank(method='min')0 25555.0
1 136.0
2 35119.0
3 336.0
4 17467.0
...
41139 25555.0
41140 28567.0
41141 21502.0
41142 21502.0
41143 13492.0
Name: city08, Length: 41144, dtype: float64city_mpg.rank(method='dense')0 14.0
1 4.0
2 18.0
3 5.0
4 12.0
...
41139 14.0
41140 15.0
41141 13.0
41142 13.0
41143 11.0
Name: city08, Length: 41144, dtype: float64make.replace('Subaru', 'スバル')0 Alfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 スバル
...
41139 スバル
41140 スバル
41141 スバル
41142 スバル
41143 スバル
Name: make, Length: 41144, dtype: objectmake.replace(r'(Fer)ra(r.*)',
value=r'\2-other-\1', regex=True)0 Alfa Romeo
1 ri-other-Fer
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: objectpd.cut(city_mpg, 10)0 (5.856, 20.4]
1 (5.856, 20.4]
2 (20.4, 34.8]
3 (5.856, 20.4]
4 (5.856, 20.4]
...
41139 (5.856, 20.4]
41140 (5.856, 20.4]
41141 (5.856, 20.4]
41142 (5.856, 20.4]
41143 (5.856, 20.4]
Name: city08, Length: 41144, dtype: category
Categories (10, interval[float64, right]): [(5.856, 20.4] < (20.4, 34.8] < (34.8, 49.2] < (49.2, 63.6] ... (92.4, 106.8] < (106.8, 121.2] < (121.2, 135.6] < (135.6, 150.0]]pd.cut(city_mpg, [0, 10, 20, 40, 70, 150])0 (10, 20]
1 (0, 10]
2 (20, 40]
3 (0, 10]
4 (10, 20]
...
41139 (10, 20]
41140 (10, 20]
41141 (10, 20]
41142 (10, 20]
41143 (10, 20]
Name: city08, Length: 41144, dtype: category
Categories (5, interval[int64, right]): [(0, 10] < (10, 20] < (20, 40] < (40, 70] < (70, 150]]pd.qcut(city_mpg, 10)0 (18.0, 20.0]
1 (5.999, 13.0]
2 (21.0, 24.0]
3 (5.999, 13.0]
4 (16.0, 17.0]
...
41139 (18.0, 20.0]
41140 (18.0, 20.0]
41141 (17.0, 18.0]
41142 (17.0, 18.0]
41143 (15.0, 16.0]
Name: city08, Length: 41144, dtype: category
Categories (10, interval[float64, right]): [(5.999, 13.0] < (13.0, 14.0] < (14.0, 15.0] < (15.0, 16.0] ... (18.0, 20.0] < (20.0, 21.0] < (21.0, 24.0] < (24.0, 150.0]]pd.qcut(city_mpg, 10, labels=list(range(1,11)))0 7
1 1
2 9
3 1
4 5
..
41139 7
41140 7
41141 6
41142 6
41143 4
Name: city08, Length: 41144, dtype: category
Categories (10, int64): [1 < 2 < 3 < 4 ... 7 < 8 < 9 < 10]city2 = city_mpg.rename(make.to_dict())
city2Alfa Romeo 19
Ferrari 9
Dodge 23
Dodge 10
Subaru 17
..
Subaru 19
Subaru 20
Subaru 18
Subaru 18
Subaru 16
Name: city08, Length: 41144, dtype: int64city2.indexIndex(['Alfa Romeo', 'Ferrari', 'Dodge', 'Dodge', 'Subaru', 'Subaru', 'Subaru',
'Toyota', 'Toyota', 'Toyota',
...
'Saab', 'Saturn', 'Saturn', 'Saturn', 'Saturn', 'Subaru', 'Subaru',
'Subaru', 'Subaru', 'Subaru'],
dtype='object', length=41144)city2 = city_mpg.rename(make)
city2Alfa Romeo 19
Ferrari 9
Dodge 23
Dodge 10
Subaru 17
..
Subaru 19
Subaru 20
Subaru 18
Subaru 18
Subaru 16
Name: city08, Length: 41144, dtype: int64city2.rename('citympg')Alfa Romeo 19
Ferrari 9
Dodge 23
Dodge 10
Subaru 17
..
Subaru 19
Subaru 20
Subaru 18
Subaru 18
Subaru 16
Name: citympg, Length: 41144, dtype: int64city2.reset_index()| index | city08 | |
|---|---|---|
| 0 | Alfa Romeo | 19 |
| 1 | Ferrari | 9 |
| 2 | Dodge | 23 |
| 3 | Dodge | 10 |
| 4 | Subaru | 17 |
| ... | ... | ... |
| 41139 | Subaru | 19 |
| 41140 | Subaru | 20 |
| 41141 | Subaru | 18 |
| 41142 | Subaru | 18 |
| 41143 | Subaru | 16 |
41144 rows × 2 columns
city2.reset_index(drop=True)0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: int64city2.loc['Subaru']Subaru 17
Subaru 21
Subaru 22
Subaru 19
Subaru 20
..
Subaru 19
Subaru 20
Subaru 18
Subaru 18
Subaru 16
Name: city08, Length: 885, dtype: int64city2.loc['Fisker']20city2.loc[['Fisker']]Fisker 20
Name: city08, dtype: int64city2.loc[['Ferrari', 'Lamborghini']]Ferrari 9
Ferrari 12
Ferrari 11
Ferrari 10
Ferrari 11
..
Lamborghini 6
Lamborghini 8
Lamborghini 8
Lamborghini 8
Lamborghini 8
Name: city08, Length: 357, dtype: int64city2.loc['Ferrari':'Lamborghini']--------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-98-ca8b99f7d7f7> in <module> ----> 1 city2.loc['Ferrari':'Lamborghini'] ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexing.py in __getitem__(self, key) 929 930 maybe_callable = com.apply_if_callable(key, self.obj) --> 931 return self._getitem_axis(maybe_callable, axis=axis) 932 933 def _is_scalar_access(self, key: tuple): ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexing.py in _getitem_axis(self, key, axis) 1140 if isinstance(key, slice): 1141 self._validate_key(key, axis) -> 1142 return self._get_slice_axis(key, axis=axis) 1143 elif com.is_bool_indexer(key): 1144 return self._getbool_axis(key, axis=axis) ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexing.py in _get_slice_axis(self, slice_obj, axis) 1174 1175 labels = obj._get_axis(axis) -> 1176 indexer = labels.slice_indexer(slice_obj.start, slice_obj.stop, slice_obj.step) 1177 1178 if isinstance(indexer, slice): ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexes/base.py in slice_indexer(self, start, end, step, kind) 5684 slice(1, 3, None) 5685 """ -> 5686 start_slice, end_slice = self.slice_locs(start, end, step=step) 5687 5688 # return a slice ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexes/base.py in slice_locs(self, start, end, step, kind) 5886 start_slice = None 5887 if start is not None: -> 5888 start_slice = self.get_slice_bound(start, "left") 5889 if start_slice is None: 5890 start_slice = 0 ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexes/base.py in get_slice_bound(self, label, side, kind) 5818 ) 5819 if isinstance(slc, np.ndarray): -> 5820 raise KeyError( 5821 f"Cannot get {side} slice bound for non-unique " 5822 f"label: {repr(original_label)}" KeyError: "Cannot get left slice bound for non-unique label: 'Ferrari'"
city2.sort_index().loc['Ferrari':'Lamborghini']Ferrari 10
Ferrari 13
Ferrari 13
Ferrari 9
Ferrari 10
..
Lamborghini 12
Lamborghini 9
Lamborghini 8
Lamborghini 13
Lamborghini 8
Name: city08, Length: 11210, dtype: int64city2.sort_index().loc["F":"J"]Federal Coach 15
Federal Coach 13
Federal Coach 13
Federal Coach 14
Federal Coach 13
..
Isuzu 15
Isuzu 15
Isuzu 15
Isuzu 27
Isuzu 18
Name: city08, Length: 9040, dtype: int64idx = pd.Index(['Dodge'])
city2.loc[idx]Dodge 23
Dodge 10
Dodge 12
Dodge 11
Dodge 11
..
Dodge 18
Dodge 17
Dodge 14
Dodge 14
Dodge 11
Name: city08, Length: 2583, dtype: int64idx = pd.Index(['Dodge', 'Dodge'])
city2.loc[idx]Dodge 23
Dodge 10
Dodge 12
Dodge 11
Dodge 11
..
Dodge 18
Dodge 17
Dodge 14
Dodge 14
Dodge 11
Name: city08, Length: 5166, dtype: int64mask = city2 > 50
maskAlfa Romeo False
Ferrari False
Dodge False
Dodge False
Subaru False
...
Subaru False
Subaru False
Subaru False
Subaru False
Subaru False
Name: city08, Length: 41144, dtype: boolcity2.loc[mask]Nissan 81
Toyota 81
Toyota 81
Ford 74
Nissan 84
...
Tesla 140
Tesla 115
Tesla 104
Tesla 98
Toyota 55
Name: city08, Length: 236, dtype: int64cost = pd.Series([1.00, 2.25, 3.99, .99, 2.79],
index=['Gum', 'Cookie', 'Melon', 'Roll', 'Carrots'])
inflation = 1.10
(cost
.mul(inflation)
.loc[lambda s_: s_ > 3]
)Melon 4.389
Carrots 3.069
dtype: float64cost = pd.Series([1.00, 2.25, 3.99, .99, 2.79],
index=['Gum', 'Cookie', 'Melon', 'Roll', 'Carrots'])
inflation = 1.10
mask = cost > 3
(cost
.mul(inflation)
.loc[mask]
)Melon 4.389
dtype: float64def gt3(s):
return s > 3gt3 = lambda s: s > 3city2.iloc[0]19city2.iloc[-1]16city2.iloc[[0,1,-1]]Alfa Romeo 19
Ferrari 9
Subaru 16
Name: city08, dtype: int64city2.iloc[0:5]Alfa Romeo 19
Ferrari 9
Dodge 23
Dodge 10
Subaru 17
Name: city08, dtype: int64city2.iloc[-8:]Saturn 21
Saturn 24
Saturn 21
Subaru 19
Subaru 20
Subaru 18
Subaru 18
Subaru 16
Name: city08, dtype: int64mask = city2 > 50
city2.iloc[mask]--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-114-59298d41640c> in <module> 1 mask = city2 > 50 ----> 2 city2.iloc[mask] ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexing.py in __getitem__(self, key) 929 930 maybe_callable = com.apply_if_callable(key, self.obj) --> 931 return self._getitem_axis(maybe_callable, axis=axis) 932 933 def _is_scalar_access(self, key: tuple): ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexing.py in _getitem_axis(self, key, axis) 1550 1551 if com.is_bool_indexer(key): -> 1552 self._validate_key(key, axis) 1553 return self._getbool_axis(key, axis=axis) 1554 ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexing.py in _validate_key(self, key, axis) 1398 "is not available" 1399 ) -> 1400 raise ValueError( 1401 "iLocation based boolean indexing cannot use " 1402 "an indexable as a mask" ValueError: iLocation based boolean indexing cannot use an indexable as a mask
city2.iloc[mask.to_numpy()]Nissan 81
Toyota 81
Toyota 81
Ford 74
Nissan 84
...
Tesla 140
Tesla 115
Tesla 104
Tesla 98
Toyota 55
Name: city08, Length: 236, dtype: int64city2.iloc[list(mask)]Nissan 81
Toyota 81
Toyota 81
Ford 74
Nissan 84
...
Tesla 140
Tesla 115
Tesla 104
Tesla 98
Toyota 55
Name: city08, Length: 236, dtype: int64city2.head(3)Alfa Romeo 19
Ferrari 9
Dodge 23
Name: city08, dtype: int64city2.tail(3)Subaru 18
Subaru 18
Subaru 16
Name: city08, dtype: int64city2.sample(6, random_state=42)Volvo 16
Mitsubishi 19
Buick 27
Jeep 15
Land Rover 13
Saab 17
Name: city08, dtype: int64city2.filter(items=['Ford', 'Subaru'])--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-121-7de9bb7e417f> in <module> ----> 1 city2.filter(items=['Ford', 'Subaru']) ~/envs/menv/lib/python3.8/site-packages/pandas/core/generic.py in filter(self, items, like, regex, axis) 4980 if items is not None: 4981 name = self._get_axis_name(axis) -> 4982 return self.reindex(**{name: [r for r in items if r in labels]}) 4983 elif like: 4984 ~/envs/menv/lib/python3.8/site-packages/pandas/core/series.py in reindex(self, index, **kwargs) 4578 ) 4579 def reindex(self, index=None, **kwargs): -> 4580 return super().reindex(index=index, **kwargs) 4581 4582 @deprecate_nonkeyword_arguments(version=None, allowed_args=["self", "labels"]) ~/envs/menv/lib/python3.8/site-packages/pandas/core/generic.py in reindex(self, *args, **kwargs) 4816 4817 # perform the reindex on the axes -> 4818 return self._reindex_axes( 4819 axes, level, limit, tolerance, method, fill_value, copy 4820 ).__finalize__(self, method="reindex") ~/envs/menv/lib/python3.8/site-packages/pandas/core/generic.py in _reindex_axes(self, axes, level, limit, tolerance, method, fill_value, copy) 4837 4838 axis = self._get_axis_number(a) -> 4839 obj = obj._reindex_with_indexers( 4840 {axis: [new_index, indexer]}, 4841 fill_value=fill_value, ~/envs/menv/lib/python3.8/site-packages/pandas/core/generic.py in _reindex_with_indexers(self, reindexers, fill_value, copy, allow_dups) 4881 4882 # TODO: speed up on homogeneous DataFrame objects -> 4883 new_data = new_data.reindex_indexer( 4884 index, 4885 indexer, ~/envs/menv/lib/python3.8/site-packages/pandas/core/internals/managers.py in reindex_indexer(self, new_axis, indexer, axis, fill_value, allow_dups, copy, consolidate, only_slice) 668 # some axes don't allow reindexing with dups 669 if not allow_dups: --> 670 self.axes[axis]._validate_can_reindex(indexer) 671 672 if axis >= self.ndim: ~/envs/menv/lib/python3.8/site-packages/pandas/core/indexes/base.py in _validate_can_reindex(self, indexer) 3783 # trying to reindex on an axis with duplicates 3784 if not self._index_as_unique and len(indexer): -> 3785 raise ValueError("cannot reindex from a duplicate axis") 3786 3787 def reindex( ValueError: cannot reindex from a duplicate axis
city2.filter(like='rd')city2.filter(regex='(Ford)|(Subaru)')city2.reindex(['Missing', 'Ford'])city_mpg.reindex([0,0, 10, 20, 2_000_000])s1 = pd.Series([10,20,30], index=['a', 'b', 'c'])
s2 = pd.Series([15,25,35], index=['b', 'c', 'd'])s2s2.reindex(s1.index)Inspect the index.
Sort the index.
Set the index to monotonically increasing integers starting from 0.
Set the index to monotonically increasing integers starting from 0, then convert these to the string version. Save this a
s2.Using
s2, pull out the first 5 entries.Using
s2, pull out the last 5 entries.Using
s2, pull out one hundred entries starting at index position 10.Using
s2, create a series with values with index entries'20','10', and'2'.
makemake.astype('string')make.astype('category')'Ford'.lower()make.str.lower()'Alfa Romeo'.find('A')make.str.find('A')make.str.extract(r'([^a-z A-Z])')(make
.str.extract(r'([^a-z A-Z])', expand=False)
.value_counts()
)age = pd.Series(['0-10', '11-15', '11-15', '61-65', '46-50'])
age0 0-10
1 11-15
2 11-15
3 61-65
4 46-50
dtype: objectage.str.split('-')0 [0, 10]
1 [11, 15]
2 [11, 15]
3 [61, 65]
4 [46, 50]
dtype: object(age
.str.split('-', expand=True)
.iloc[:,0]
.astype(int)
)0 0
1 11
2 11
3 61
4 46
Name: 0, dtype: int64(age
.str.slice(-2)
.astype(int)
)0 10
1 15
2 15
3 65
4 50
dtype: int64(age
.str[-2:]
.astype(int)
)0 10
1 15
2 15
3 65
4 50
dtype: int64(age
.str.split('-', expand=True)
.astype(int)
.mean(axis='columns')
)0 5.0
1 13.0
2 13.0
3 63.0
4 48.0
dtype: float64import random
def between(row):
return random.randint(*row.values)(age
.str.split('-', expand=True)
.astype(int)
.apply(between, axis='columns')
)0 2
1 15
2 15
3 62
4 50
dtype: int64make.str.replace('A', 'Å')0 Ålfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: objectmake.replace('A', 'Å')0 Alfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: objectmake.replace({'Audi': 'Åudi', 'Acura': 'Åcura',
'Ashton Martin': 'Åshton Martin',
'Alfa Romeo': 'Ålfa Romeo'})0 Ålfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: objectmake.replace('A', 'Å', regex=True)0 Ålfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: objectUsing a string column, lowercase the values.
Using a string column, slice out the first character.
Using a string column, slice out the last three characters.
Using a string column, create a series extracting the numeric values.
Using a string column, create a series extracting the non-ASCII values.
Using a string column, create a dataframe with the dummy columns for every character in the column.
col = pd.Series(['2015-03-08 08:00:00+00:00',
'2015-03-08 08:30:00+00:00',
'2015-03-08 09:00:00+00:00',
'2015-03-08 09:30:00+00:00',
'2015-11-01 06:30:00+00:00',
'2015-11-01 07:00:00+00:00',
'2015-11-01 07:30:00+00:00',
'2015-11-01 08:00:00+00:00',
'2015-11-01 08:30:00+00:00',
'2015-11-01 08:00:00+00:00',
'2015-11-01 08:30:00+00:00',
'2015-11-01 09:00:00+00:00',
'2015-11-01 09:30:00+00:00',
'2015-11-01 10:00:00+00:00'])utc_s = pd.to_datetime(col, utc=True)
utc_s0 2015-03-08 08:00:00+00:00
1 2015-03-08 08:30:00+00:00
2 2015-03-08 09:00:00+00:00
3 2015-03-08 09:30:00+00:00
4 2015-11-01 06:30:00+00:00
...
9 2015-11-01 08:00:00+00:00
10 2015-11-01 08:30:00+00:00
11 2015-11-01 09:00:00+00:00
12 2015-11-01 09:30:00+00:00
13 2015-11-01 10:00:00+00:00
Length: 14, dtype: datetime64[ns, UTC]utc_s.dt.tz_convert('America/Denver')0 2015-03-08 01:00:00-07:00
1 2015-03-08 01:30:00-07:00
2 2015-03-08 03:00:00-06:00
3 2015-03-08 03:30:00-06:00
4 2015-11-01 00:30:00-06:00
...
9 2015-11-01 01:00:00-07:00
10 2015-11-01 01:30:00-07:00
11 2015-11-01 02:00:00-07:00
12 2015-11-01 02:30:00-07:00
13 2015-11-01 03:00:00-07:00
Length: 14, dtype: datetime64[ns, America/Denver]s = pd.Series(['2015-03-08 01:00:00-07:00',
'2015-03-08 01:30:00-07:00',
'2015-03-08 03:00:00-06:00',
'2015-03-08 03:30:00-06:00',
'2015-11-01 00:30:00-06:00',
'2015-11-01 01:00:00-06:00',
'2015-11-01 01:30:00-06:00',
'2015-11-01 01:00:00-07:00',
'2015-11-01 01:30:00-07:00',
'2015-11-01 01:00:00-07:00',
'2015-11-01 01:30:00-07:00',
'2015-11-01 02:00:00-07:00',
'2015-11-01 02:30:00-07:00',
'2015-11-01 03:00:00-07:00'])pd.to_datetime(s, utc=True).dt.tz_convert('America/Denver')0 2015-03-08 01:00:00-07:00
1 2015-03-08 01:30:00-07:00
2 2015-03-08 03:00:00-06:00
3 2015-03-08 03:30:00-06:00
4 2015-11-01 00:30:00-06:00
...
9 2015-11-01 01:00:00-07:00
10 2015-11-01 01:30:00-07:00
11 2015-11-01 02:00:00-07:00
12 2015-11-01 02:30:00-07:00
13 2015-11-01 03:00:00-07:00
Length: 14, dtype: datetime64[ns, America/Denver]time = pd.Series(['2015-03-08 01:00:00',
'2015-03-08 01:30:00',
'2015-03-08 02:00:00',
'2015-03-08 02:30:00',
'2015-03-08 03:00:00',
'2015-03-08 02:00:00',
'2015-03-08 02:30:00',
'2015-03-08 03:00:00',
'2015-03-08 03:30:00',
'2015-11-01 00:30:00',
'2015-11-01 01:00:00',
'2015-11-01 01:30:00',
'2015-11-01 02:00:00',
'2015-11-01 02:30:00',
'2015-11-01 01:00:00',
'2015-11-01 01:30:00',
'2015-11-01 02:00:00',
'2015-11-01 02:30:00',
'2015-11-01 03:00:00'])offset = pd.Series([-7, -7, -7, -7, -7, -6, -6,
-6, -6, -6, -6, -6, -6, -6, -7, -7, -7, -7, -7])(pd.to_datetime(time)
.groupby(offset)
.transform(lambda s: s.dt.tz_localize(s.name)
.dt.tz_convert('America/Denver'))
)0 2015-03-07 18:00:07-07:00
1 2015-03-07 18:30:07-07:00
2 2015-03-07 19:00:07-07:00
3 2015-03-07 19:30:07-07:00
4 2015-03-07 20:00:07-07:00
...
14 2015-10-31 19:00:07-06:00
15 2015-10-31 19:30:07-06:00
16 2015-10-31 20:00:07-06:00
17 2015-10-31 20:30:07-06:00
18 2015-10-31 21:00:07-06:00
Length: 19, dtype: datetime64[ns, America/Denver]offset = offset.replace({-7:'-07:00', -6:'-06:00'})
local = (pd.to_datetime(time)
.groupby(offset)
.transform(lambda s: s.dt.tz_localize(s.name)
.dt.tz_convert('America/Denver'))
)local0 2015-03-08 01:00:00-07:00
1 2015-03-08 01:30:00-07:00
2 2015-03-08 03:00:00-06:00
3 2015-03-08 03:30:00-06:00
4 2015-03-08 04:00:00-06:00
...
14 2015-11-01 01:00:00-07:00
15 2015-11-01 01:30:00-07:00
16 2015-11-01 02:00:00-07:00
17 2015-11-01 02:30:00-07:00
18 2015-11-01 03:00:00-07:00
Length: 19, dtype: datetime64[ns, America/Denver]local.dt.tz_convert('UTC')0 2015-03-08 08:00:00+00:00
1 2015-03-08 08:30:00+00:00
2 2015-03-08 09:00:00+00:00
3 2015-03-08 09:30:00+00:00
4 2015-03-08 10:00:00+00:00
...
14 2015-11-01 08:00:00+00:00
15 2015-11-01 08:30:00+00:00
16 2015-11-01 09:00:00+00:00
17 2015-11-01 09:30:00+00:00
18 2015-11-01 10:00:00+00:00
Length: 19, dtype: datetime64[ns, UTC]secs = local.view(int).floordiv(1e9).astype(int)
secs0 1425801600
1 1425803400
2 1425805200
3 1425807000
4 1425808800
...
14 1446364800
15 1446366600
16 1446368400
17 1446370200
18 1446372000
Length: 19, dtype: int64(pd.to_datetime(secs, unit='s')
.dt.tz_localize('UTC'))0 2015-03-08 08:00:00+00:00
1 2015-03-08 08:30:00+00:00
2 2015-03-08 09:00:00+00:00
3 2015-03-08 09:30:00+00:00
4 2015-03-08 10:00:00+00:00
...
14 2015-11-01 08:00:00+00:00
15 2015-11-01 08:30:00+00:00
16 2015-11-01 09:00:00+00:00
17 2015-11-01 09:30:00+00:00
18 2015-11-01 10:00:00+00:00
Length: 19, dtype: datetime64[ns, UTC]url = 'https://github.com/mattharrison/datasets'+\
'/raw/master/data/alta-noaa-1980-2019.csv'
alta_df = pd.read_csv(url)dates = pd.to_datetime(alta_df.DATE)
dates0 1980-01-01
1 1980-01-02
2 1980-01-03
3 1980-01-04
4 1980-01-05
...
14155 2019-09-03
14156 2019-09-04
14157 2019-09-05
14158 2019-09-06
14159 2019-09-07
Name: DATE, Length: 14160, dtype: datetime64[ns]dates.dt.day_name('es_ES')0 Martes
1 Miércoles
2 Jueves
3 Viernes
4 Sábado
...
14155 Martes
14156 Miércoles
14157 Jueves
14158 Viernes
14159 Sábado
Name: DATE, Length: 14160, dtype: objectdates.dt.is_month_end0 False
1 False
2 False
3 False
4 False
...
14155 False
14156 False
14157 False
14158 False
14159 False
Name: DATE, Length: 14160, dtype: booldates.dt.strftime('%d/%m/%y')0 01/01/80
1 02/01/80
2 03/01/80
3 04/01/80
4 05/01/80
...
14155 03/09/19
14156 04/09/19
14157 05/09/19
14158 06/09/19
14159 07/09/19
Name: DATE, Length: 14160, dtype: objectConvert a column with date information to a date.
Convert a date column into UTC dates.
Convert a date column into local dates with a timezone.
Convert a date column into epoch values.
Convert an epoch number into UTC.
url = 'https://github.com/mattharrison/datasets'+\
'/raw/master/data/alta-noaa-1980-2019.csv'
alta_df = pd.read_csv(url)
dates = pd.to_datetime(alta_df.DATE)snow = (alta_df
.SNOW
.rename(dates)
)snow1980-01-01 2.0
1980-01-02 3.0
1980-01-03 1.0
1980-01-04 0.0
1980-01-05 0.0
...
2019-09-03 0.0
2019-09-04 0.0
2019-09-05 0.0
2019-09-06 0.0
2019-09-07 0.0
Name: SNOW, Length: 14160, dtype: float64snow.isna().any()Truesnow[snow.isna()]1985-07-30 NaN
1985-09-12 NaN
1985-09-19 NaN
1986-02-07 NaN
1986-06-26 NaN
..
2017-04-26 NaN
2017-09-20 NaN
2017-10-02 NaN
2017-12-23 NaN
2018-12-03 NaN
Name: SNOW, Length: 365, dtype: float64snow.loc['1985-09':'1985-09-20']1985-09-01 0.0
1985-09-02 0.0
1985-09-03 0.0
1985-09-04 0.0
1985-09-05 0.0
...
1985-09-16 0.0
1985-09-17 0.0
1985-09-18 0.0
1985-09-19 NaN
1985-09-20 0.0
Name: SNOW, Length: 20, dtype: float64(snow
.loc['1985-09':'1985-09-20']
.fillna(0)
)1985-09-01 0.0
1985-09-02 0.0
1985-09-03 0.0
1985-09-04 0.0
1985-09-05 0.0
...
1985-09-16 0.0
1985-09-17 0.0
1985-09-18 0.0
1985-09-19 0.0
1985-09-20 0.0
Name: SNOW, Length: 20, dtype: float64snow.loc['1987-12-30':'1988-01-10']1987-12-30 6.0
1987-12-31 5.0
1988-01-01 NaN
1988-01-02 0.0
1988-01-03 0.0
...
1988-01-06 6.0
1988-01-07 4.0
1988-01-08 9.0
1988-01-09 5.0
1988-01-10 2.0
Name: SNOW, Length: 12, dtype: float64(snow
.loc['1987-12-30':'1988-01-10']
.ffill()
)1987-12-30 6.0
1987-12-31 5.0
1988-01-01 5.0
1988-01-02 0.0
1988-01-03 0.0
...
1988-01-06 6.0
1988-01-07 4.0
1988-01-08 9.0
1988-01-09 5.0
1988-01-10 2.0
Name: SNOW, Length: 12, dtype: float64(snow
.loc['1987-12-30':'1988-01-10']
.bfill()
)1987-12-30 6.0
1987-12-31 5.0
1988-01-01 0.0
1988-01-02 0.0
1988-01-03 0.0
...
1988-01-06 6.0
1988-01-07 4.0
1988-01-08 9.0
1988-01-09 5.0
1988-01-10 2.0
Name: SNOW, Length: 12, dtype: float64(snow
.loc['1987-12-30':'1988-01-10']
.interpolate()
)1987-12-30 6.0
1987-12-31 5.0
1988-01-01 2.5
1988-01-02 0.0
1988-01-03 0.0
...
1988-01-06 6.0
1988-01-07 4.0
1988-01-08 9.0
1988-01-09 5.0
1988-01-10 2.0
Name: SNOW, Length: 12, dtype: float64winter = (snow.index.quarter == 1) | (snow.index.quarter== 4)
(snow
.where(~(winter & snow.isna()), snow.interpolate())
.where(~(~winter & snow.isna()), 0)
)1980-01-01 2.0
1980-01-02 3.0
1980-01-03 1.0
1980-01-04 0.0
1980-01-05 0.0
...
2019-09-03 0.0
2019-09-04 0.0
2019-09-05 0.0
2019-09-06 0.0
2019-09-07 0.0
Name: SNOW, Length: 14160, dtype: float64(snow
.where(~(winter & snow.isna()), snow.interpolate())
.where(~(~winter & snow.isna()), 0)
.loc[['1985-09-19','1988-01-01']]
)1985-09-19 0.0
1988-01-01 2.5
Name: SNOW, dtype: float64(snow
.loc['1987-12-30':'1988-01-10']
.dropna()
)1987-12-30 6.0
1987-12-31 5.0
1988-01-02 0.0
1988-01-03 0.0
1988-01-05 2.0
1988-01-06 6.0
1988-01-07 4.0
1988-01-08 9.0
1988-01-09 5.0
1988-01-10 2.0
Name: SNOW, dtype: float64snow.shift(1)1980-01-01 NaN
1980-01-02 2.0
1980-01-03 3.0
1980-01-04 1.0
1980-01-05 0.0
...
2019-09-03 0.0
2019-09-04 0.0
2019-09-05 0.0
2019-09-06 0.0
2019-09-07 0.0
Name: SNOW, Length: 14160, dtype: float64snow.shift(-1)1980-01-01 3.0
1980-01-02 1.0
1980-01-03 0.0
1980-01-04 0.0
1980-01-05 1.0
...
2019-09-03 0.0
2019-09-04 0.0
2019-09-05 0.0
2019-09-06 0.0
2019-09-07 NaN
Name: SNOW, Length: 14160, dtype: float64(snow
.add(snow.shift(1))
.add(snow.shift(2))
.add(snow.shift(3))
.add(snow.shift(4))
.div(5)
)1980-01-01 NaN
1980-01-02 NaN
1980-01-03 NaN
1980-01-04 NaN
1980-01-05 1.2
...
2019-09-03 0.0
2019-09-04 0.0
2019-09-05 0.0
2019-09-06 0.0
2019-09-07 0.0
Name: SNOW, Length: 14160, dtype: float64(snow
.rolling(5)
.mean()
)1980-01-01 NaN
1980-01-02 NaN
1980-01-03 NaN
1980-01-04 NaN
1980-01-05 1.2
...
2019-09-03 0.0
2019-09-04 0.0
2019-09-05 0.0
2019-09-06 0.0
2019-09-07 0.0
Name: SNOW, Length: 14160, dtype: float64(snow
.resample('M')
.max()
)1980-01-31 20.0
1980-02-29 25.0
1980-03-31 16.0
1980-04-30 10.0
1980-05-31 9.0
...
2019-05-31 5.1
2019-06-30 0.0
2019-07-31 0.0
2019-08-31 0.0
2019-09-30 0.0
Freq: M, Name: SNOW, Length: 477, dtype: float64(snow
.resample('2M')
.max()
)1980-01-31 20.0
1980-03-31 25.0
1980-05-31 10.0
1980-07-31 1.0
1980-09-30 0.0
...
2019-01-31 19.0
2019-03-31 20.7
2019-05-31 18.0
2019-07-31 0.0
2019-09-30 0.0
Freq: 2M, Name: SNOW, Length: 239, dtype: float64(snow
.resample('A-MAY')
.max()
)1980-05-31 25.0
1981-05-31 26.0
1982-05-31 34.0
1983-05-31 38.0
1984-05-31 25.0
...
2016-05-31 15.0
2017-05-31 26.0
2018-05-31 21.8
2019-05-31 20.7
2020-05-31 0.0
Freq: A-MAY, Name: SNOW, Length: 41, dtype: float64(snow
.div(snow
.resample('Q')
.transform('sum'))
.mul(100)
.fillna(0)
)1980-01-01 0.527009
1980-01-02 0.790514
1980-01-03 0.263505
1980-01-04 0.000000
1980-01-05 0.000000
...
2019-09-03 0.000000
2019-09-04 0.000000
2019-09-05 0.000000
2019-09-06 0.000000
2019-09-07 0.000000
Name: SNOW, Length: 14160, dtype: float64season2017 = snow.loc['2016-10':'2017-05']
(season2017
.resample('M')
.sum()
.div(season2017
.sum())
.mul(100)
)2016-10-31 2.153969
2016-11-30 9.772637
2016-12-31 15.715995
2017-01-31 25.468688
2017-02-28 21.041085
2017-03-31 9.274033
2017-04-30 14.738732
2017-05-31 1.834862
Freq: M, Name: SNOW, dtype: float64def season(idx):
year = idx.year
month = idx.month
return year.where((month < 10), year+1)(snow
.groupby(season)
.sum()
)1980 457.5
1981 503.0
1982 842.5
1983 807.5
1984 816.0
...
2015 284.3
2016 354.6
2017 524.0
2018 308.8
2019 504.5
Name: SNOW, Length: 40, dtype: float64(snow
.resample('A-SEP')
.sum()
)1980-09-30 457.5
1981-09-30 503.0
1982-09-30 842.5
1983-09-30 807.5
1984-09-30 816.0
...
2015-09-30 284.3
2016-09-30 354.6
2017-09-30 524.0
2018-09-30 308.8
2019-09-30 504.5
Freq: A-SEP, Name: SNOW, Length: 40, dtype: float64(snow
.loc['2016-10':'2017-09']
.cumsum()
)2016-10-01 0.0
2016-10-02 0.0
2016-10-03 4.9
2016-10-04 4.9
2016-10-05 5.5
...
2017-09-26 524.0
2017-09-27 524.0
2017-09-28 524.0
2017-09-29 524.0
2017-09-30 524.0
Name: SNOW, Length: 364, dtype: float64(snow
.resample('A-SEP')
.transform('cumsum')
)1980-01-01 2.0
1980-01-02 5.0
1980-01-03 6.0
1980-01-04 6.0
1980-01-05 6.0
...
2019-09-03 504.5
2019-09-04 504.5
2019-09-05 504.5
2019-09-06 504.5
2019-09-07 504.5
Name: SNOW, Length: 14160, dtype: float64Convert a column with date information to a date.
Put the date information into the index for a numeric column.
Calculate the average value of the column for each month.
Calculate the average value of the column for every 2 months.
Calculate the percentage of the column out of the total for each month.
Calculate the average value of the column for a rolling window of size 7.
Using
.locpull out the first 3 months of a year.Using
.locpull out the last 4 months of a year.
url = 'https://github.com/mattharrison/datasets/raw/master/'\
'data/alta-noaa-1980-2019.csv'
alta_df = pd.read_csv(url) # doctest: +SKIP
dates = pd.to_datetime(alta_df.DATE)
snow = (alta_df
.SNOW
.rename(dates)
)snow1980-01-01 2.0
1980-01-02 3.0
1980-01-03 1.0
1980-01-04 0.0
1980-01-05 0.0
...
2019-09-03 0.0
2019-09-04 0.0
2019-09-05 0.0
2019-09-06 0.0
2019-09-07 0.0
Name: SNOW, Length: 14160, dtype: float64snow.plot.hist() # doctest: +SKIP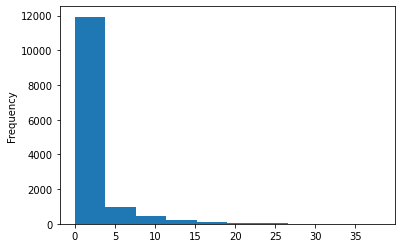
snow[snow>0].plot.hist(bins=20, title='Snowfall Histogram (in)') # doctest: +SKIP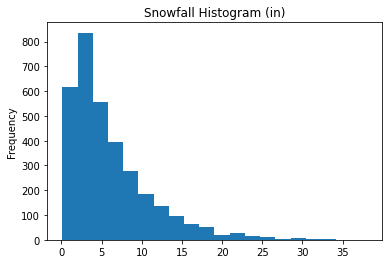
snow.plot.box()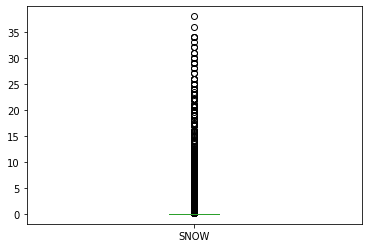
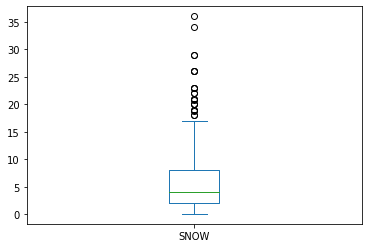
(snow
[lambda s:(s.index.month == 1) & (s>0)]
.plot.box()
)
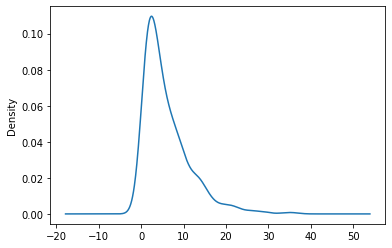
(snow
[lambda s:(s.index.month == 1) & (s>0)]
.plot.kde()
)
snow.plot.line()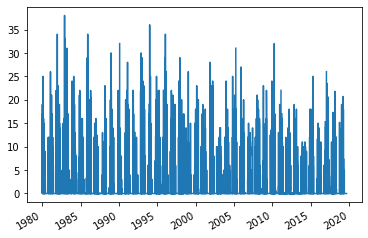
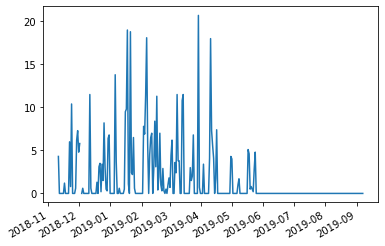
(snow
.iloc[-300:]
.plot.line()
)
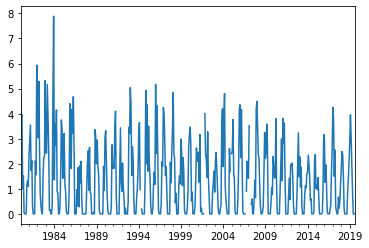
(snow
.resample('M')
.mean()
.plot.line()
)
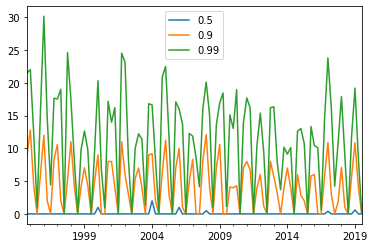
(snow
.resample('Q')
.quantile([.5, .9, .99])
.unstack()
.iloc[-100:]
.plot.line()
)
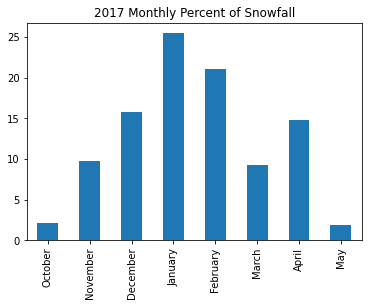
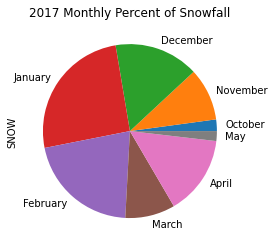
season2017 = (snow.loc['2016-10':'2017-05'])
(season2017
.resample('M')
.sum()
.div(season2017.sum())
.mul(100)
.rename(lambda idx: idx.month_name())
)October 2.153969
November 9.772637
December 15.715995
January 25.468688
February 21.041085
March 9.274033
April 14.738732
May 1.834862
Name: SNOW, dtype: float64(season2017
.resample('M')
.sum()
.div(season2017.sum())
.mul(100)
.rename(lambda idx: idx.month_name())
.plot.bar(title='2017 Monthly Percent of Snowfall')
)
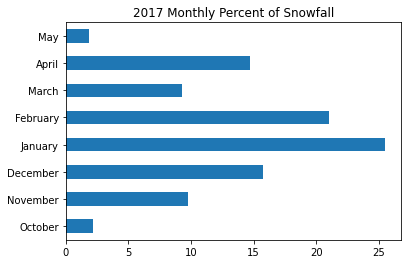
(season2017
.resample('M')
.sum()
.div(season2017.sum())
.mul(100)
.rename(lambda idx: idx.month_name())
.plot.barh(title='2017 Monthly Percent of Snowfall')
)
url = 'https://github.com/mattharrison/datasets/raw/master/data/'\
'vehicles.csv.zip'
df = pd.read_csv(url) # doctest: +SKIP
make = df.make/home/matt/envs/menv/lib/python3.8/site-packages/IPython/core/interactiveshell.py:3418: DtypeWarning: Columns (68,70,71,72,73,74,76,79) have mixed types.Specify dtype option on import or set low_memory=False.
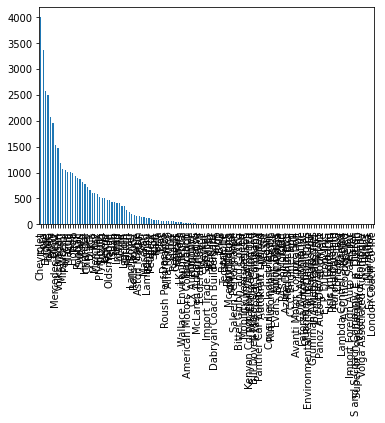
exec(code_obj, self.user_global_ns, self.user_ns)make.value_counts()Chevrolet 4003
Ford 3371
Dodge 2583
GMC 2494
Toyota 2071
...
Volga Associated Automobile 1
Panos 1
Mahindra 1
Excalibur Autos 1
London Coach Co Inc 1
Name: make, Length: 136, dtype: int64(make
.value_counts()
.plot.bar()
)
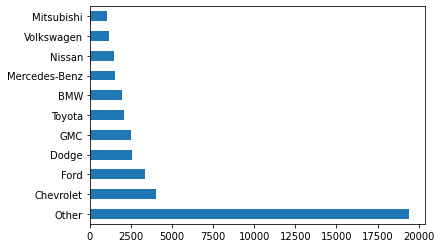
top10 = make.value_counts().index[:10]
(make
.where(make.isin(top10), 'Other')
.value_counts()
.plot.barh()
)
(season2017
.resample('M')
.sum()
.div(season2017.sum())
.mul(100)
.rename(lambda idx: idx.month_name())
.plot.pie(title='2017 Monthly Percent of Snowfall')
)
import pandas as pd
url = 'https://github.com/mattharrison/datasets/raw/master/' \
'data/vehicles.csv.zip'
df = pd.read_csv(url) # doctest: +SKIP
make = df.make
make/home/matt/envs/menv/lib/python3.8/site-packages/IPython/core/interactiveshell.py:3418: DtypeWarning: Columns (68,70,71,72,73,74,76,79) have mixed types.Specify dtype option on import or set low_memory=False.
exec(code_obj, self.user_global_ns, self.user_ns)0 Alfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: objectmake.value_counts()Chevrolet 4003
Ford 3371
Dodge 2583
GMC 2494
Toyota 2071
...
Volga Associated Automobile 1
Panos 1
Mahindra 1
Excalibur Autos 1
London Coach Co Inc 1
Name: make, Length: 136, dtype: int64make.shape, make.nunique()((41144,), 136)cat_make = make.astype('category')make.memory_usage(deep=True)2606395cat_make.memory_usage(deep=True)95888%%timeitUsageError: %%timeit is a cell magic, but the cell body is empty. Did you mean the line magic %timeit (single %)?%%timeitmake_type = pd.CategoricalDtype(
categories=sorted(make.unique()), ordered=True)
ordered_make = make.astype(make_type)
ordered_make0 Alfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: category
Categories (136, object): ['AM General' < 'ASC Incorporated' < 'Acura' < 'Alfa Romeo' ... 'Volvo' < 'Wallace Environmental' < 'Yugo' < 'smart']ordered_make.max()'smart'cat_make.max()--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-208-0dd04fc39a22> in <module> ----> 1 cat_make.max() ~/envs/menv/lib/python3.8/site-packages/pandas/core/generic.py in max(self, axis, skipna, level, numeric_only, **kwargs) 10817 ) 10818 def max(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs): > 10819 return NDFrame.max(self, axis, skipna, level, numeric_only, **kwargs) 10820 10821 setattr(cls, "max", max) ~/envs/menv/lib/python3.8/site-packages/pandas/core/generic.py in max(self, axis, skipna, level, numeric_only, **kwargs) 10362 10363 def max(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs): > 10364 return self._stat_function( 10365 "max", nanops.nanmax, axis, skipna, level, numeric_only, **kwargs 10366 ) ~/envs/menv/lib/python3.8/site-packages/pandas/core/generic.py in _stat_function(self, name, func, axis, skipna, level, numeric_only, **kwargs) 10352 name, axis=axis, level=level, skipna=skipna, numeric_only=numeric_only 10353 ) > 10354 return self._reduce( 10355 func, name=name, axis=axis, skipna=skipna, numeric_only=numeric_only 10356 ) ~/envs/menv/lib/python3.8/site-packages/pandas/core/series.py in _reduce(self, op, name, axis, skipna, numeric_only, filter_type, **kwds) 4381 if isinstance(delegate, ExtensionArray): 4382 # dispatch to ExtensionArray interface -> 4383 return delegate._reduce(name, skipna=skipna, **kwds) 4384 4385 else: ~/envs/menv/lib/python3.8/site-packages/pandas/core/arrays/_mixins.py in _reduce(self, name, skipna, **kwargs) 255 meth = getattr(self, name, None) 256 if meth: --> 257 return meth(skipna=skipna, **kwargs) 258 else: 259 msg = f"'{type(self).__name__}' does not implement reduction '{name}'" ~/envs/menv/lib/python3.8/site-packages/pandas/util/_decorators.py in wrapper(*args, **kwargs) 205 else: 206 kwargs[new_arg_name] = new_arg_value --> 207 return func(*args, **kwargs) 208 209 return cast(F, wrapper) ~/envs/menv/lib/python3.8/site-packages/pandas/core/arrays/categorical.py in max(self, skipna, **kwargs) 2145 nv.validate_minmax_axis(kwargs.get("axis", 0)) 2146 nv.validate_max((), kwargs) -> 2147 self.check_for_ordered("max") 2148 2149 if not len(self._codes): ~/envs/menv/lib/python3.8/site-packages/pandas/core/arrays/categorical.py in check_for_ordered(self, op) 1643 """assert that we are ordered""" 1644 if not self.ordered: -> 1645 raise TypeError( 1646 f"Categorical is not ordered for operation {op}\n" 1647 "you can use .as_ordered() to change the " TypeError: Categorical is not ordered for operation max you can use .as_ordered() to change the Categorical to an ordered one
ordered_make.sort_values()20288 AM General
20289 AM General
369 AM General
358 AM General
19314 AM General
...
31289 smart
31290 smart
29605 smart
22974 smart
26882 smart
Name: make, Length: 41144, dtype: category
Categories (136, object): ['AM General' < 'ASC Incorporated' < 'Acura' < 'Alfa Romeo' ... 'Volvo' < 'Wallace Environmental' < 'Yugo' < 'smart']cat_make.cat.rename_categories(
[c.lower() for c in cat_make.cat.categories])0 alfa romeo
1 ferrari
2 dodge
3 dodge
4 subaru
...
41139 subaru
41140 subaru
41141 subaru
41142 subaru
41143 subaru
Name: make, Length: 41144, dtype: category
Categories (136, object): ['am general', 'asc incorporated', 'acura', 'alfa romeo', ..., 'volvo', 'wallace environmental', 'yugo', 'smart']ordered_make.cat.rename_categories(
{c:c.lower() for c in ordered_make.cat.categories})0 alfa romeo
1 ferrari
2 dodge
3 dodge
4 subaru
...
41139 subaru
41140 subaru
41141 subaru
41142 subaru
41143 subaru
Name: make, Length: 41144, dtype: category
Categories (136, object): ['am general' < 'asc incorporated' < 'acura' < 'alfa romeo' ... 'volvo' < 'wallace environmental' < 'yugo' < 'smart']ordered_make.cat.reorder_categories(
sorted(cat_make.cat.categories, key=str.lower))0 Alfa Romeo
1 Ferrari
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: category
Categories (136, object): ['Acura' < 'Alfa Romeo' < 'AM General' < 'American Motors Corporation' ... 'Volvo' < 'VPG' < 'Wallace Environmental' < 'Yugo']ordered_make.iloc[:100].value_counts()Dodge 17
Oldsmobile 8
Ford 8
Buick 7
Chevrolet 5
..
Grumman Allied Industries 0
Goldacre 0
Geo 0
Genesis 0
smart 0
Name: make, Length: 136, dtype: int64(cat_make
.iloc[:100]
.groupby(cat_make.iloc[:100])
.first()
)make
AM General NaN
ASC Incorporated NaN
Acura NaN
Alfa Romeo Alfa Romeo
American Motors Corporation NaN
...
Volkswagen Volkswagen
Volvo Volvo
Wallace Environmental NaN
Yugo NaN
smart NaN
Name: make, Length: 136, dtype: category
Categories (136, object): ['AM General', 'ASC Incorporated', 'Acura', 'Alfa Romeo', ..., 'Volvo', 'Wallace Environmental', 'Yugo', 'smart'](make
.iloc[:100]
.groupby(make.iloc[:100])
.first()
)make
Alfa Romeo Alfa Romeo
Audi Audi
BMW BMW
Buick Buick
CX Automotive CX Automotive
...
Rolls-Royce Rolls-Royce
Subaru Subaru
Toyota Toyota
Volkswagen Volkswagen
Volvo Volvo
Name: make, Length: 25, dtype: object(cat_make
.iloc[:100]
.groupby(cat_make.iloc[:100], observed=True)
.first()
)make
Alfa Romeo Alfa Romeo
Ferrari Ferrari
Dodge Dodge
Subaru Subaru
Toyota Toyota
...
Mazda Mazda
Oldsmobile Oldsmobile
Plymouth Plymouth
Pontiac Pontiac
Rolls-Royce Rolls-Royce
Name: make, Length: 25, dtype: category
Categories (136, object): ['AM General', 'ASC Incorporated', 'Acura', 'Alfa Romeo', ..., 'Volvo', 'Wallace Environmental', 'Yugo', 'smart']ordered_make.iloc[0]'Alfa Romeo'ordered_make.iloc[[0]]0 Alfa Romeo
Name: make, dtype: category
Categories (136, object): ['AM General' < 'ASC Incorporated' < 'Acura' < 'Alfa Romeo' ... 'Volvo' < 'Wallace Environmental' < 'Yugo' < 'smart']def generalize_topn(ser, n=5, other='Other'):
topn = ser.value_counts().index[:n]
if isinstance(ser.dtype, pd.CategoricalDtype):
ser = ser.cat.set_categories(
topn.set_categories(list(topn)+[other]))
return ser.where(ser.isin(topn), other)cat_make.pipe(generalize_topn, n=20, other='NA')0 NA
1 NA
2 Dodge
3 Dodge
4 Subaru
...
41139 Subaru
41140 Subaru
41141 Subaru
41142 Subaru
41143 Subaru
Name: make, Length: 41144, dtype: category
Categories (21, object): ['Chevrolet', 'Ford', 'Dodge', 'GMC', ..., 'Volvo', 'Hyundai', 'Chrysler', 'NA']def generalize_mapping(ser, mapping, default):
seen = None
res = ser.astype(str)
for old, new in mapping.items():
mask = ser.str.contains(old)
if seen is None:
seen = mask
else:
seen |= mask
res = res.where(~mask, new)
res = res.where(seen, default)
return res.astype('category')generalize_mapping(cat_make, {'Ford': 'US', 'Tesla': 'US',
'Chevrolet': 'US', 'Dodge': 'US',
'Oldsmobile': 'US', 'Plymouth': 'US',
'BMW': 'German'}, 'Other')0 Other
1 Other
2 US
3 US
4 Other
...
41139 Other
41140 Other
41141 Other
41142 Other
41143 Other
Name: make, Length: 41144, dtype: category
Categories (3, object): ['German', 'Other', 'US']